Avec la grande excitation actuelle autour de l’apprentissage machine et de l’intelligence artificielle, il faut se rappeler que les algorithmes ne doivent pas se résumer pas à de l’analyse probabiliste mais qu’ils doivent être également orchestrés à l’aide de référentiels gérés et gouvernés pour structurer, extraire correctement l’information et y donner accès de façon contextualisée – je préfère cette notion à celle d’intelligente – : c’est l’humain qui prend des décisions intelligentes, l’information n’est pas intelligente en soi, ni la gestion automatisée de celle-ci – pas encore.
L’humain a la responsabilité de contrôler les biais de la quantité. Des éléments qualitatifs (qui ne s’assimilent pas au ‘sentiment analysis’) et extrinsèques aux algorithmes doivent aussi contribuer à la construction du contexte, et de là au savoir et/ou à la décision.
L’apprentissage machine et les analytiques textuelles sont avant tout des instruments pour aider à traiter la masse de données et d’informations disponibles, mais ne sont certainement pas un remplacement du jugement de l’humain pour en tirer de l’intelligence. Le but est d’accélérer le traitement des flux et des stocks d’information, l’humain doit apprendre à comprendre et utiliser correctement cet outil, être vigilant face aux promesses de « vérité », et veiller à ne pas se décharger de son rôle moral: c’est le résultat de la machine et des procédures donc je ne suis pas responsable… L’histoire pas si lointaine (ex: certains, selon des critères pré-établis, sont plus humains que d’autres, donc on peut les écarter, voire les exterminer…) nous a montré où l’instrumentalisation peut mener, que cela implique des machines ou non.
Pour le moment, l’intelligence artificielle ne peut que reproduire les schémas humains (voir *1) puisque le corpus qui est traité est un sous-ensemble de ce que l’humain a lui-même créé, sélectionné pour traitement, selon des modèles dessinés par ceux-ci en fonction d’un objectif soit scientifique, soit commercial, soit de surveillance.
Tout est toujours question de perspective. Le travail entourant les algorithmes, que ce soit dès l’entrée de données, la sélections des sources de données, le traitement et le nettoyage des données, est avant tout un travail d’édition et de curation parce que cela implique de privilégier certains scénarios et certaines hypothèses plutôt que d’autres. C’est le travail d’équipe d’individus de profils différents mais complémentaires.
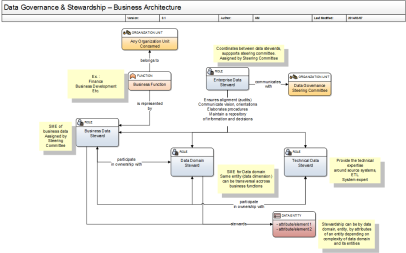
Parmi les rôles requis ne se trouvent pas uniquement les scientifiques de données (les statisticiens, les actuaires, les économétristes, etc.)
mais aussi ceux qui participent également à la sélection des référentiels utiles, jugent de leur validité intrinsèque et extrinsèque, orchestrent les liens entre les sources d’information pour l’exploration, modélisent des structures de base pour que l’algorithme normalise et nettoie les entités structurelles,
d’où viennent ceux qui ont ces compétences?
Certains penseront informatique: gestion des bases de données, développeurs ETL, etc.
D’autres penseront intelligence d’affaire (BI).
Pourtant, il s’agit plus d’un état d’esprit que de compétences issues d’une formation académique.
Vous trouverez aussi d’excellents candidats auprès des métiers financiers (à la fin de chaque année financière une armada de champions Excel sont mobilisés pour nettoyer et arranger des sources financières pour consolider les comptes et compenser pour ce qui semble être des incohérences au moment de cet exercice), du développement des affaires …
ET des sciences de l’information…
Aux États-Unis et dans le Canada anglophone, cette reconnaissance de compétence pour ces derniers est présente, mais l’est beaucoup moins au Québec par les francophones…
…. et ainsi permettre aux scientifiques de données de passer moins de temps à nettoyer les données et plus à les analyser et à bâtir des visualisations efficaces.
À ce jour, la machine n’est pas intelligente, elle respecte des scénarios scriptés par des humains, il ne faut pas l’oublier. Cela n’empêche pas de constater et d’apprécier sa puissance.
Il y a effectivement de quoi s’inquiéter (voir *2) si l’opacité concernant les scénarios privilégiés, justifiée au nom de la propriété intellectuelle, nuit à la compréhension des résultats et à la transparence des décisions, et empêche de connaître la portée des morceaux d’information qui sont jugés ‘pertinents’ d’être exposés ou non dans différents contextes et quelles sont les hypothèses retenues. Cependant, l’exclusion du droit d’accès au financement, aux assurances et autres profilages a précédé l’existence de l’intelligence artificielle; ce qui change, c’est la rapidité, le volume et l’automatisation (décision assistée par ordinateur) et le risque (cité plus haut) de désengagement moral et d’accentuation de la déshumanisation, via la rarification à l’extrême de la compassion, face à des situations qui entrainent l’exclusion et le déni d’accès à certains services sous prétexte de critères arbitraires qui classent les uns et les autres dans une catégorie ou une autre. L’arbitraire précède les algorithmes et est la source analogique de ces algorithmes, seulement maintenant cet arbitraire est traité automatiquement et en masse par des machines. Des mécanismes d’appel aux décisions devront être plus accessibles et facilités pour compenser l’absence de compassion. L’humain peut avoir de la compassion, pas la machine.
Filed under: Ère du numérique, Classification, Gestion de l'information, Knowledge Management